

Advantages of Scraping Data from Alternate Sources such as PDF, XML & JSON

A data source in an unusual format, such as PDF, XML, or JSON, is just as significant as a web page.
For more than 10 years, iWeb Scraping has been a prominent participant in the web scraping game. We extract data from both basic and complicated sources as a DaaS platform, while keeping the highest quality requirements.
Web pages are the most popular data sources for the data extraction services you get. However, we do occasionally get requests from clients who want their data from offline and unusual sources including PDF files, XML, and JSON.
We'll look at how we gather data from various non-traditional data sources and formats in this section.
PDF Documents

Portable Document Format is the abbreviation for Portable Document Format. They were created by Adobe and are one of the most often used digital replacements for paper material.
PDF files are one of the most widely used formats for storing and communicating information in businesses. Their cross-platform accessibility allows for not just simple document mobility (as the name implies), but also easy reading and storing. Using PDF documents, you may keep any information in one place for convenient viewing and reading, whether it's textual, graphical, or scanned.
The Advantages of utilizing a PDF file format
- PDF files are exceedingly useful and efficient, providing a variety of advantages, including:
- Usability and consistency across many platforms
- The format is simple to read and understand.
- The ability to store a variety of material, such as text, photos, and even scanned book documents.
- Watermarks, autographs, and other critical material can be preserved in this protected layout.
Data Extraction from PDF Documents

Unlike other types of documents, such as Word and Excel files, PDF files do not allow for easy modification, which makes data extraction much more difficult. Data scraping from PDF files is difficult because its primary purpose is to provide a secure layout. If not done correctly, it might result in excessively unstructured data, which makes the fundamental goal of data extraction - effective analysis. After all, you don't want to end up with data that is confusing, partial, or nonsensical, which defeats the point of having good data to work with.
Learn about How iWeb Scraping Handles PDF Data Extraction?
- When we get a PDF scraping request, we first look at the document's layout and level of complexity to determine how much data can be extracted.
- We save the file in a text-friendly format, such as Word.
- The document inserts a line break at the end of the paragraph when it is exported. While these new lines are not visible, they increase the scraper's difficulties while parsing the page.
- To overcome this, we use regular expressions (RegEx) to detect and eliminate every new line, leaving paragraph and section breaks alone.
- We then extract data fields as needed, depending on the structure.
- Some document formats (columns, for example) add to the difficulty. When you require data from one of the rows in the first column, we gather bits of that row from the other columns with several whitespace characters in between (like a tab — 4–5 characters).
- In such circumstances, we divide the gathered text using whitespace as a separator and save the data as arrays. The array index is then used to map each individual string to its parent field.
- Similarly, extracting information from a PDF that has a big list of items, such as goods, would necessitate more complicated and powerful web scrapers. To meet the increased memory requirements, more resources in terms of RAM and storage would be required.
Parsing Data from XML Sources
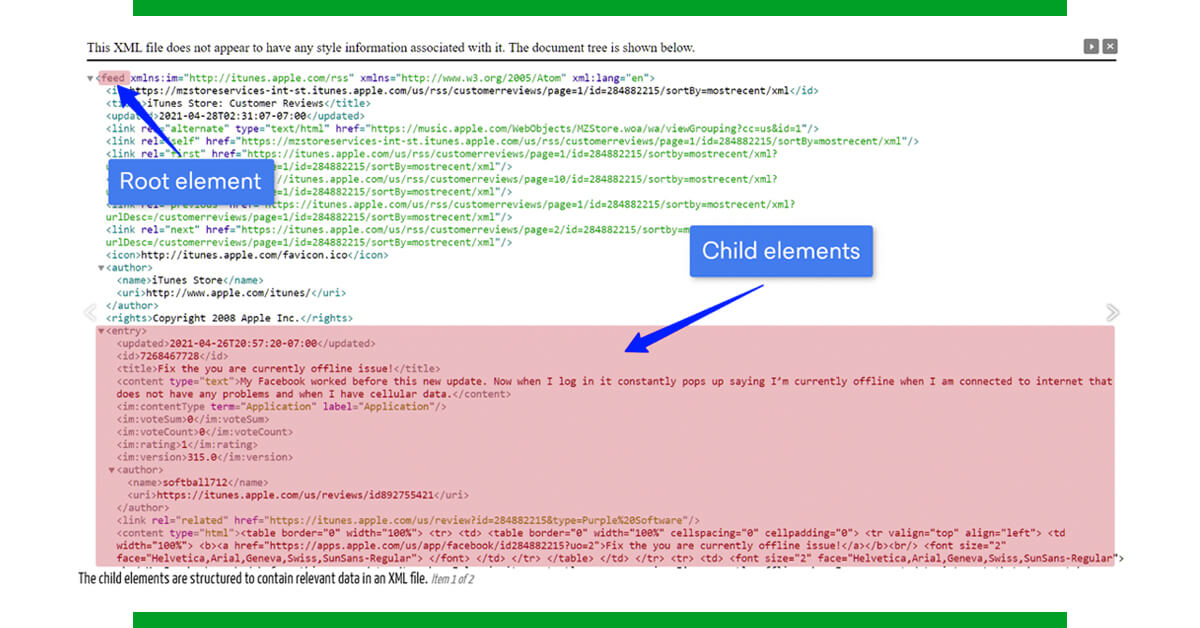
- eXtensible Markup Language is the abbreviation for eXtensible Markup Language. It specifies a set of criteria that enable a document to be read by both humans and machines.
- As seen in the graphic below, data is stored in XML files as element trees, with a root (or parent) element that branches into child elements. Following that, these components are retrieved based on the request.
In some use cases, the XML files also include sitemaps for websites that include links to their listings, such as goods. After we've displayed the product URLs, we'll extract the data in the same way we would any other online data.
However, it isn't always that easy. Some sitemaps have poorly organized categories and subcategories. This complicates an already tough data extraction source.
Data Parsing in JSON Format

JSON (JavaScript Object Notation) is a simple data storage and transmission format. When data is transferred from a server to a web page, it is frequently utilized.
JSON files contain data in the form of name-value pairs, making them simple to read and write for people as well as for machines to process and produce. JSON is the best data-interchange format since it is totally language-independent text format.
JSON data is arranged in parent and child components, similar to XML files, making data collecting simple. The majority of websites visible on-screen is usually included as JSON in the web page's JavaScript code. It is feasible to discover the JSON resource, extract the relevant data, then format and organize them into their appropriate data fields as desired by evaluating the website's source code.
As more businesses choose different ways to store their data, we don't want any company to miss out on achieving their goals simply because the data they need is kept in an unusual format. No one should be missing out on money because they can't extract data in an organized and editable way.
Let us know your requirement for any kind of web scraping services.
Contact iWeb Scraping today!