

How to Extract Product Data from Walmart with Python and BeautifulSoup

Walmart is the leading retailer with both online stores as well as physical stores around the world. Having a larger product variety in the portfolio with $519.93 Billion of net sales, Walmart is dominating the retail market as well as it also provides ample data, which could be utilized to get insights on product portfolios, customer’s behavior, as well as market trends.
In this tutorial blog, we will extract product data from Walmart s well as store that in the SQL databases. We use Python for scraping a website. The package used for the scraping exercise is called BeautifulSoup. Together with that, we have also utilized Selenium as it helps us interact with Google Chrome.
Scrape Walmart Product Data
The initial step is importing all the required libraries. When, we import the packages, let’s start by setting the scraper’s flow. For modularizing the code, we initially investigated the URL structure of Walmart product pages. A URL is an address of a web page, which a user refers to as well as can be utilized for uniquely identifying the page.
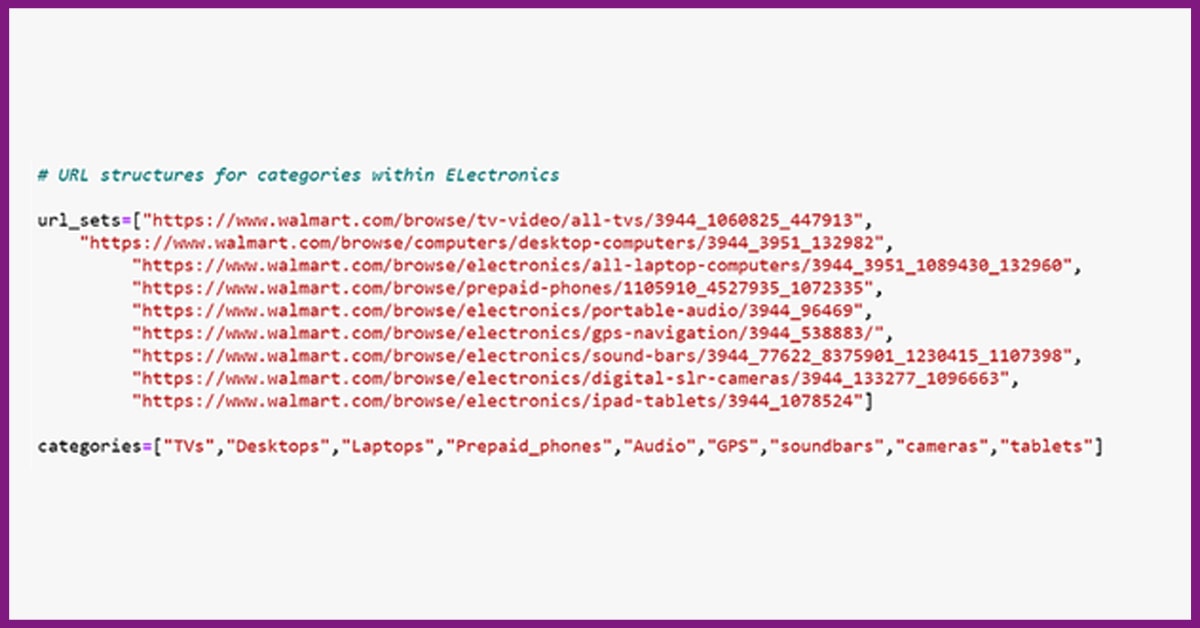
Here, in the given example, we have made a listing of page URLs within Walmart’s electronics department. We also have made the list of names of different product categories. We would use them in future to name the tables or datasets.
You may add as well as remove the subcategories for all major product categories. All you require to do is going to subcategory pages as well as scrape the page URL. The address is general for all the available products on the page. You may also do that for maximum product categories. In the given image, we have showed categories including Toys and Food for the demo.
In addition, we have also stored URLs in the list because it makes data processing in Python much easier. When, we have all the lists ready, let’s move on for writing a scraper.
Also, we have made a loop for automating the extraction exercise. Although, we can run that for only one category as well as subcategory also. Let us pretend, we wish to extract data for only one sub-category like TVs in ‘Electronics’ category. Later on, we will exhibit how to scale a code for all the sub-categories.

Here, a variable pg=1 makes sure that we are extracting data for merely the first URL within an array ‘url_sets’ i.e. merely for the initial subcategory in main category. When you complete that, the following step might be to outline total product pages that you would wish to open for scraping data from. To do this, we are extracting data from the best 10 pages.
Then, we loop through a complete length of top_n array i.e. 10 times for opening the product pages as well as scrape a complete webpage structure in HTML form code. It is like inspecting different elements of web page as well as copying the resultants’ HTML code. Although, we have more added a limitation that only a part of HTML structure, which lies in a tag ‘Body’ is scraped as well as stored as the object. That is because applicable product data is only within a page’s HTML body.
This entity can be used for pulling relevant product data for different products, which were listed on an active page. For doing that, we have identified that a tag having product data is the ‘div’ tag having a class, ‘search-result-gridview-item-wrapper’. Therefore, in next step, we have used a find_all function for scraping all the occurrences from the given class. We have stored this data in the temporary object named ‘codelist’.

After that, we have built the URL of separate products. For doing so, we have observed that different product pages begin with a basic string called ‘https://walmart.com/ip’. All unique-identifies were added only before this string. A unique identifier was similar as a string values scraped from a ‘search-result-gridview-item-wrapper’ items saved above. Therefore, in the following step, we have looped through a temporary object code list, for constructing complete URL of any particular product’ page.
Want to Scrape Product Data
From Walmart?

With this URL, we will be able to scrape particular product-level data. To do this demo, we have got details like unique Product codes, Product’s name, Product page URL, Product_description, name of current page’s category where a product is positioned, name of the active subcategory where the product is positioned on a website (which is called active breadcrumb), Product pricing, ratings (Star ratings), number of reviews or ratings for a product as well as other products suggested on the Walmart’s site similar or associated to a product. You may customize this listing according to your convinience.

The code given above follows the following step of opening an individual product page, based on the constructed URLs as well as scraping the products’ attributes, as given in the listing above. When you are okay with a listing of attributes getting pulled within a code, the last step for a scraper might be to attach all the product data in the subcategory within a single frame data. The code here shows that.
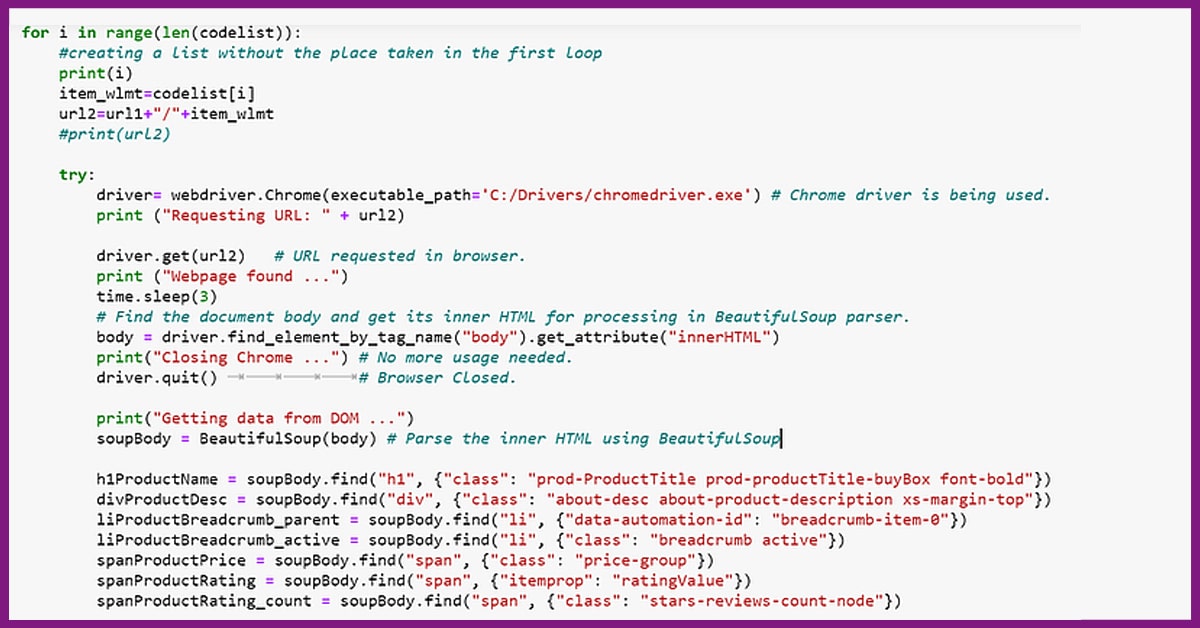
A data frame called ‘df’ would have all the data for products on the best 10 pages of a chosen subcategory within your code. You may either write data on the CSV files or distribute it to the SQL database. In case, you need to export that to the MySQL database within the table named ‘product_info’, you may utilize the code given below:

You would need to provide the SQL database credentials and when you do it, Python helps you to openly connect the working environment with the database as well as push the dataset straight as the SQL dataset. In the above code, in case the table having that name exists already, the recent code would replace with the present table. You may always change a script to evade doing so. Python provides you an option to 'fail', 'append', or 'replace' data here.
It is the basic code structure, which can be improved to add exclusions to deal with missing data or later loading pages. In case, you choose to loop the code for different subcategories, a complete code would look like:



