

About Wikipedia?
Wikipedia is a totally free online encyclopedia, created as well as edited by volunteers around the world and hosted by the Wikimedia Foundation. Currently, Wikipedia is having more than 5+ million articles written in English. At iWeb Scraping, we provide the Best Wikipedia Description Scraping Services to extract data from Wikipedia dumps or descriptions.
We make a script, which uses Wikipedia or Wikidata for scraping a short bio of the website lists. We provide Wikipedia Dumps Scraping Services. We create a script, which takes in the flat file about the domain names as well as gives results in a CSV having three columns: Domain_Name, Wikipedia_Description, and Wikipedia_Page_URL.
Our Wikipedia Dump Scraping Services make that easier to scrape data from Wikipedia’s HTML webpages. They are particularly designed for scraping Wikipedia dump data so that you may convert composite scraping operations into easy and simply contained pieces. Before continuing further, it is important to get easy understandings about HTML or XML web structures.
Product/Services Highlights
Our Wikipedia Dump Data Scraper extracts all the information alongside Update Checking. At iWeb Scraping, we save extracted data into CSV or Excel format. We scrape details in spite of any massive or complicated supply for you in the necessary formats. We provide support for different proxies.
Despite being dependable and well-organized compared to the manual web scraping, data scraper saves time, sources, as well as thousands of man-hours that can be utilized for other respected business procedures. Our customized Wikipedia Dump Data Extractor is particularly designed as per the individual’s business requirements and the pricing will vary relying on the targeted websites, algorithms’ difficulties, and flexibility for controlling the scraping patterns.
Reseller’s Management
Manage the channel partners as well as resellers by scraping product information from various retailer websites. More data processing can disclose in case, there are various terms of infringement violations.
Listing Of Data Fields
At iWeb Scraping, we scrape the following data fields for Wikipedia Dump Descriptions Data Scraping Services:
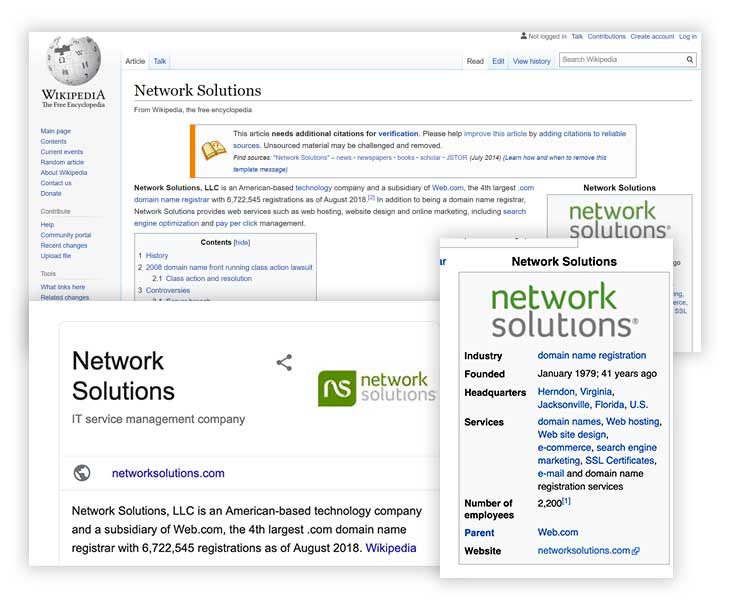
You need to ensure that appointed Wikipedia Dump Scraping Services perform what is required before paying any money or you might require to pay for Wikipedia Dump Data Scraper, which doesn’t have the best results.
Why Choose Us?
Our customer support team will help you know directly in case of any problem while using the Wikipedia Dumps data extraction services. Our Wikipedia description data extractor services are skilled, dependable, and give faster results with no errors.
Our expert team works for the Wikipedia Description Data Scraper to assist you with the required data.
Our skilled team understands how to change unstructured data into structured data. Our Wikipedia Description Data Extractors track various pages of directed websites to have the required results.
Our Wikipedia Dump Scraping Services will save you valuable money and time. We can perform research for data in some hours, which might take some days or even weeks if you do that to your own.
Request a Quote
We use the time and money of customers through automating their data abstractions using smooth data scraping services.

Testimonials
That’s What Our Clients Say
Here are some words of praise from clients who have used our web scraping services. Their feedback and trusted words always make us feel happier.











I have used web scraping services from iWeb Scraping for an online job extraction procedure, and their work was accurate and really cost-effective. I would certainly use their services in the future for our data extraction requirements.
David WatsoniWeb Scraping provides best data extraction services in a prompt and professional manner. We had a web scraping requirement for online product submission in OsCommerce website and extracting products information and images from eBay and Amazon and they have done a wonderful job.
Robert MorisI am really impressed with the data scraping services of iWeb Scraping. There services were quick, seamless, precise, and risk-free. Their data extraction services have been outstanding and we are completely satisfied with the final outcomes.
Rebecca SudanMy first experience with iWeb Scraping for a small data extraction task was excellent. After that, I repeatedly used their web scraping services Service and I can surely tell you that it is the best web scraping Services Company I have worked with! I am really impressed with their data extraction services.
Sandra BernhardiWeb Scraping has been a real asset for our business. It’s really hard to get a company which can offer web scraping, web data extraction, screen scraping, and screen scraper work with really high speed & accuracy.
Elizabeth Nelson

