

How Python Is Used to Build a Web Crawler using Bypassing Anti-Crawler Technology?

Some individuals acquire specific essential information and employ web crawlers for data capture as the Internet has grown and web crawler technology has become more widespread. Web crawlers, on the other hand, drain the network system's resources while also posing a risk of core data theft. As a result, the majority of businesses have implemented anti-crawlers. This page covers the basics of web crawlers, including their concepts and dangers, as well as typical anti-crawler methods.
Defining a Web Crawler
A web crawler, sometimes known as a web spider, is a web robot that can automatically extract web page information according to particular rules and is used to automatically traverse the World Wide Web. Web crawlers are mostly used to gather network resources. Search engines utilize web crawlers to browse material and save pages so that indexes may be created for users to search later.
Where is Web Crawler Used?
Data monitoring is focusing on a small set of critical data, noting changes, and updating it.
- Data collection: storing the dataset in a local or cloud database
- Information Gathering: Collect data from many systems and merge it into a single table.
- Collecting resources: Gather media files such as photos, movies, and MP3s.
How Does Web Crawler Work?
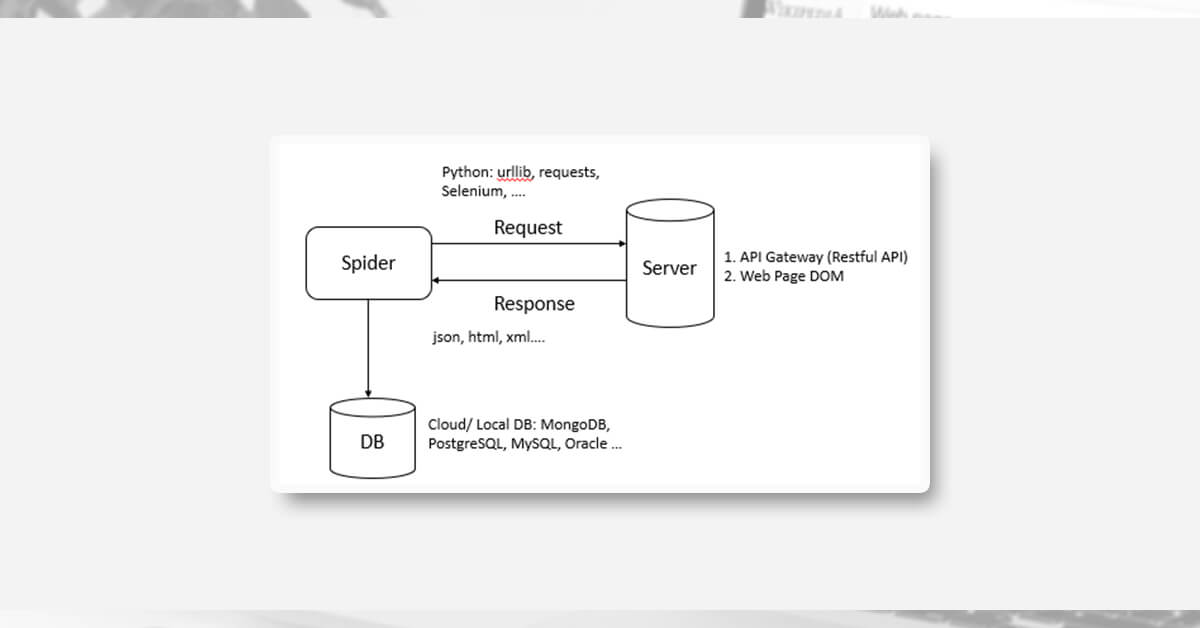
A web crawler is broken into two steps in general:
Step 1: Requests are sent to the server in the first step (URL)
Step 2: Crawl the entire HTML data or a subset of it
Method 1: Simple Program Script to Get All the URLs
import requests
from bs4 import BeautifulSoup
domain = 'https://www.google.com/search?q='
search = 'Web Scraping'
response = requests.get(domain+search)
soup = BeautifulSoup(response.content, 'html.parser')
elm = [x['href'][x['href'].find('https'):] for x in soup.select('a') if '/url?q=' in x['href']]
for e in elm:
print('Main URL',e)
response = requests.get(e)
soup = BeautifulSoup(response.content, 'html.parser')
url = [x['href'] for x in soup.select('a') if x.has_attr('href') and 'https' in x['href']]
print('Sub URL',url)
Code Explanation
- To receive data from a specific URL and put it in a response variable, use the GET technique.
- Process response information as HTML using BeautifulSoup
- Locate all anchor elements and retrieve the HREF property
- Go to every URL
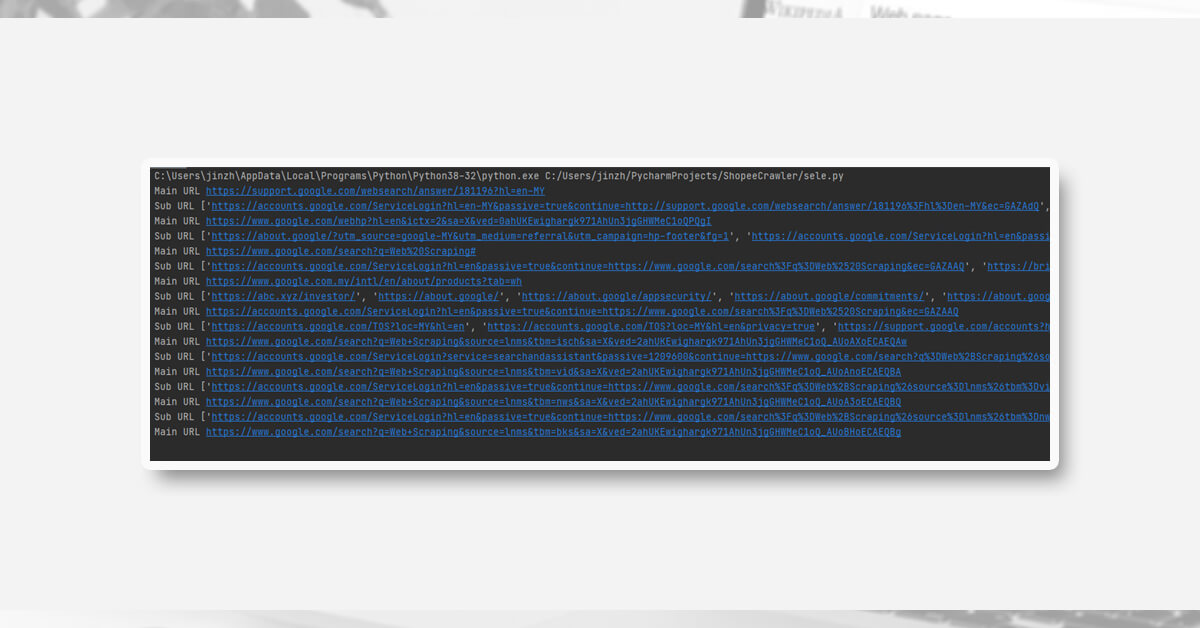
Output
Method 2: Building a Selenium App to Crawl the URLs
from selenium import webdriver
import numpy as np
import time
driver = webdriver.Chrome()
domain = 'https://www.google.com/search?q='
search = 'Web Scraping'
driver.get(domain+search)
time.sleep(5)
elm = [x.get_attribute('href') for x in driver.find_elements_by_tag_name('a') if x.get_attribute('href') != None]
for e in elm:
print('Main URL', e)
driver.get(e)
time.sleep(5)
url = np.unique([x.get_attribute('href') for x in driver.find_elements_by_tag_name('a') if x.get_attribute('href') != None and x.get_attribute('href').startswith('https')]).tolist()
print('Sub URL', url)
driver.quit()
Explaining Code
- Install the Chrome Driver.
- Go to the Home Page.
- Extract the HREF attribute from all anchor tags.
- Continue to collect URLs inside the sub-branch by visiting all URLs that capture.
Method 3: Building a Selenium App using BS4 to crawl all the URLs
from selenium import webdriver
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
domain = 'https://www.google.com/search?q='
search = 'Web Scraping'
driver.get(domain+search)
time.sleep(5)
DOM = driver.page_source
soup = BeautifulSoup(DOM, 'html.parser')
elm = [x['href'] for x in soup.select('a') if x.has_attr('href') and x['href'].startswith('https')]
for e in elm:
print('Main URL', e)
driver.get(e)
time.sleep(5)
DOM = driver.page_source
soup = BeautifulSoup(DOM, 'html.parser')
url = [x['href'] for x in soup.select('a') if x.has_attr('href') and 'https' in x['href']]
print('Sub URL', url)
driver.quit()
Code Explanation
- Run the Chrome Driver for the first time.
- Go to the Home Page
- Get the Page Source for Web Elements and parse it into BeautifulSoup to get all the HREF properties.
- Continue to collect URLs inside sub-branch by visiting all URLs that capture.
Output
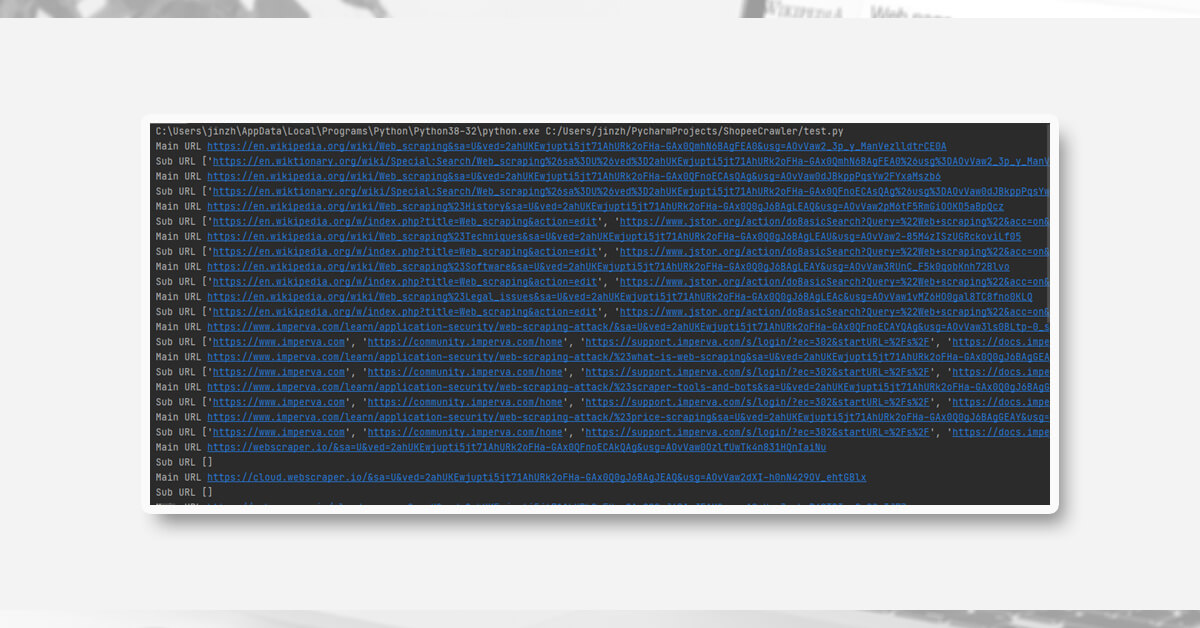
What are the similarities and limits of the three programs?
Similarity:
- Make requests or look around the website.
- Remove the DOM Element as well as the HTML tag element.
- Using a loop to extract all URLs included within the main URL
Limitations
1. When comparing the performance of these three programs, the first program has the greatest results; it can prevent some of the web element issues that typically occur in Selenium, but it is not recommended for websites that need authentication.
2. Selenium is an excellent choice for various activities like user authentication, data export, and so on, however, some businesses deploy anti-reptile technology to prevent developers from grabbing data from their website.
The Risks of Web Crawlers
The crawler access process will consume a large number of system resources: the crawler's access speed is much faster than that of normal users; the crawler may also consume a large amount of server bandwidth, increasing the server's load; and the crawler program may issue a large number of requests in a short amount of time. Users' regular access is being hampered, and the network is being clogged.
Sequential RPA Program
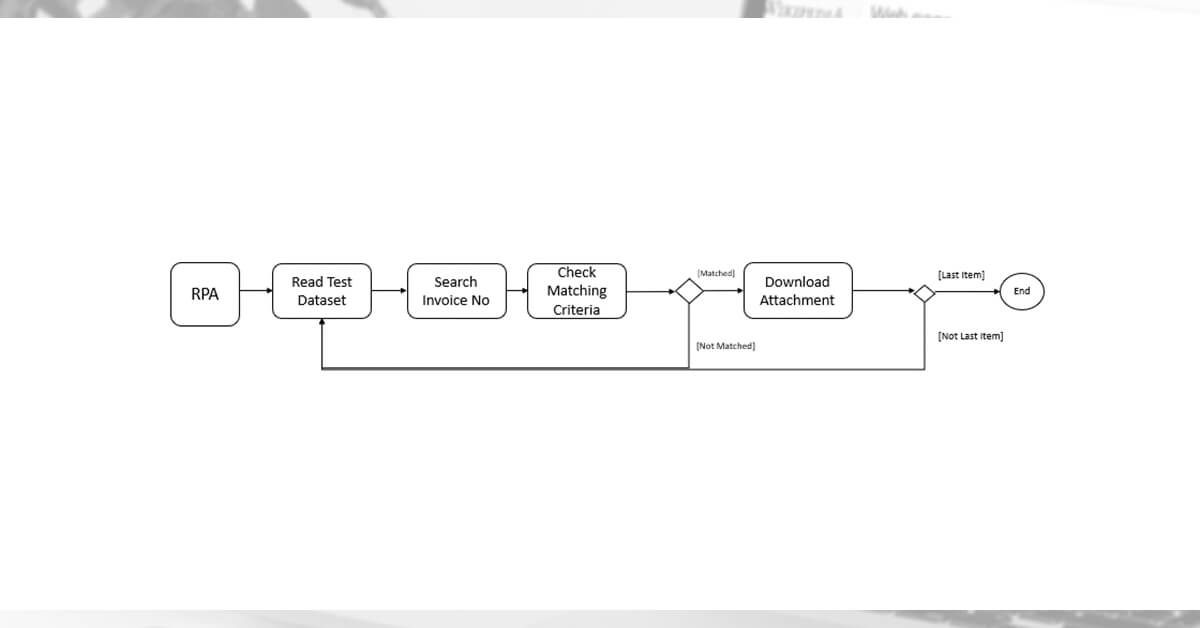
You can make a program to evaluate the system's functionality, throughput, and availability as a software or system tester. For sequential programs, the system can still manage a standard crawler operation, resulting in a 5% increase in database I/O. But it'll be a different scenario if you add parallel programming to the RPA application.
Parallel RPA Program
1. One application is divided into 16 threads and executed on four computers, for a total of 52 operating processes. The number of threads is determined by the specs of the laptop or server, which include the number of core processors. Each machine's maximum speed has been boosted by about 16 times. Data was retrieved faster utilizing parallel programming than with a sequential approach, saving roughly 52 hours of data collecting time. As we all know, online scraping may take a long time to collect data from the internet. Parallel programming is one approach for speeding up the process, but it uses a lot of system resources.
2. Website content and data security problems: The website's content and data have become its essential competitiveness, and data theft might result in a loss of competitiveness. As a result, many websites will include anti-crawling techniques to prevent crawling by programs other than search engines.
Anti-Reply Technology
The batch acquisition is one of the crawlers' most fundamental capabilities, and the anti-crawling mechanism assesses and conducts anti-crawling based on this feature.
Limit IP Addresses: Set the single IP access threshold. If an IP address's access frequency exceeds the threshold in a short period, the IP can be temporarily blocked; the IP's request frequency is tracked; if it is constantly at the same frequency, it is quite probable that the IP is malicious. It's a reptile, thus it should be prohibited.
Solution: Implement random time sleep to evade system detection while lowering performance.
time.sleep(random.randint(0, 30))
Based on Headers: Headers are the simplest method to tell the difference between browser and machine activity. Each browser's user agent is fixed when it visits a website, and the web crawler's user agent is usually empty. Examine the visit's request header. It will be identified as a robot user if it is in the form of a crawler framework, and a 403 error will be returned with No Access.
Solution: Copy the browser's header information and paste it into the software.
Include Human-Machine Identification Security Code: The main purpose of verification code as a human-machine identification technique is to distinguish between normal and machine activities and to detect harmful behavior. In the face of OCR and neural networks, traditional graphic verification codes are becoming obsolete. A new generation of behavior verification codes is suggested. Deep learning is used to execute human-machine judgement rapidly and correctly, and it has a high level of security.
Solution: Image processing or text recognition using the triangular prism
Asynchronous Data Loading: Web pages are updated asynchronously. Solution: Image processing, or word recognition utilizing the tesseract. The HTML code at the start of a webpage is crawled by the crawler, not the code after an asynchronous refresh. The protected section of the website can be asynchronously loaded into HTML using AJAX technology, allowing users to view it normally while simultaneously protecting the content from web spiders.
Solution: Use Selenium to extract a specific piece of data after it has been rendered on the page.
Cookies and Login: Examine the cookie value to see if the access request is from a crawler, and then anti-crawl by logging in to cookies.
Solution: Look at the cookie information and add them when the software starts up.
The use of all of the anti-crawling solutions listed above can significantly reduce the influence of web crawlers.
For any web scraping services, contact iWeb Scraping today!!
Request for a quote!