
How to Bypass Anti-Scraping Tools on Websites?

To survive in today’s competitive market, businesses utilize all the methods to gain an advantage. Web scraping is the only way for businesses to acquire this kind of dominance. However, this isn't a field without challenges. Anti-scraping methods are used by websites to prevent you from scraping their content. However, there will always be a way out.
What is Web Scraping?
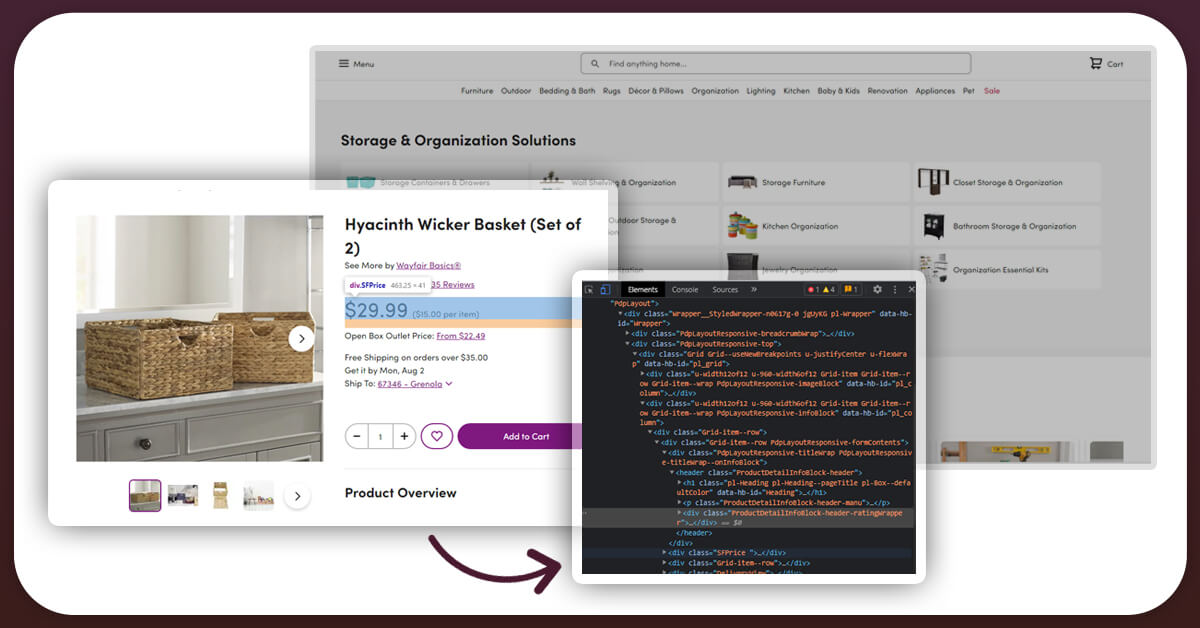
Extracting data from various websites is what web scraping API is all about. Information such as product pricing and discounts can be extracted. The information you gather can help you improve the user experience. Customers will choose you above your competitors as a result of this information. For example, e-commerce businesses selling software will learn how to enhance the product. You may then compare your costs to those of your competitors. Finally, you can determine how much your program will cost and also what features need to be upgraded. This method can be used on practically any product.
What are Anti-Scraping Tools and How to Deal with Them?

For an initial startup, you will need to focus on targeted and well-established sites.
What is the Role of Anti-Scraping Tools?
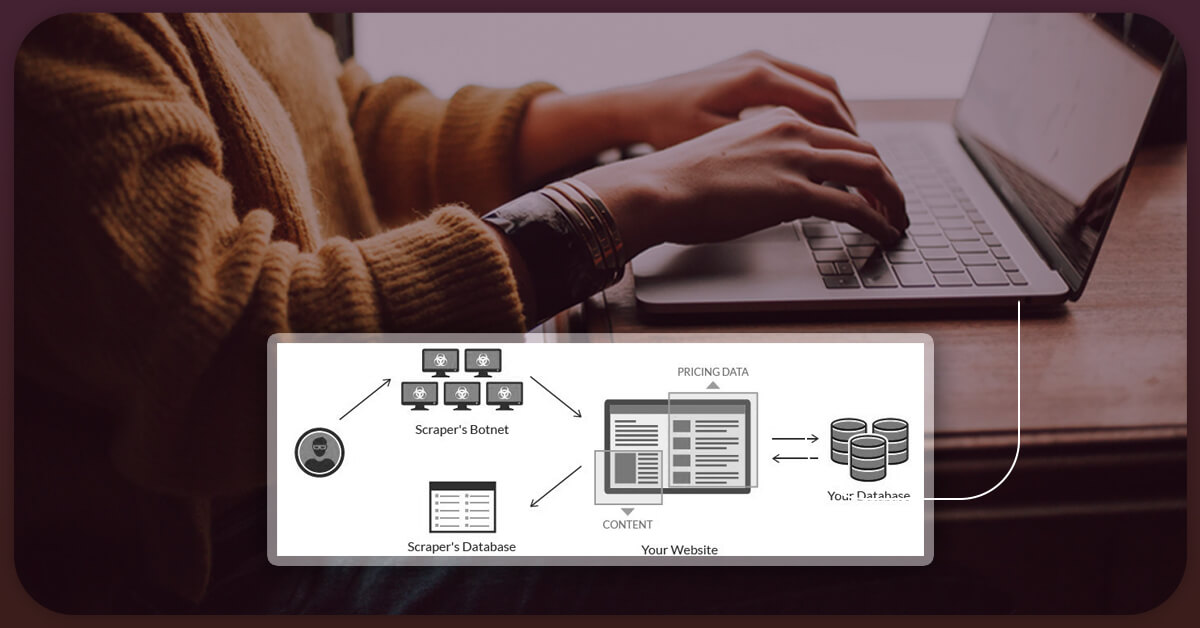
Websites contain a wealth of information. Authentic visitors will use these skills to understand something new or choose a product to purchase. However, non-genuine visitors such as those from competitor websites can exploit this information to gain a competitive edge. Anti-scraping tools are used by websites to maintain their competitors. Anti-scraping software can detect fake visitors and restrict them from gathering information for their purpose.
Anti-scraping techniques can range from simple IP address identification to advanced JavaScript verification. Let's have a look at a few techniques to get through even the most severe anti-scraping measures.
1. Rotate Your IP Address
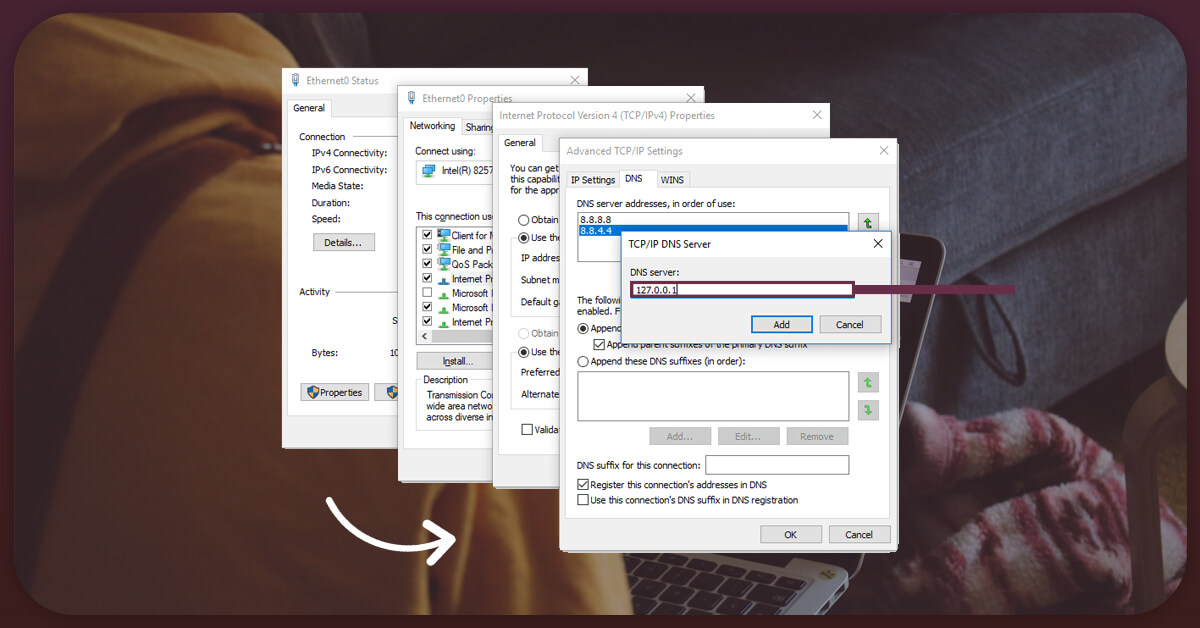
This will be the simplest technique to deceive any anti-scraping software. A device's IP address is similar to a number identifier. When you access a site to execute web scraping, you can easily keep track of it. Many websites keep track of the IP addresses from which their visitors access them. As a result, you should maintain many IP addresses available while performing the massive operation of scraping a major website. None of your IP addresses will be blacklisted if you use several of these.
This strategy applies to the majority of websites. However, complex proxy blacklists are used by some high-profile websites. That's where you'll need to be more strategic. Proxies from your home or on your phone are also viable options. There are various types of proxies, in case you were wondering. The world has a limited amount of IP addresses. However, if you manage to gather a thousand of them, you can quickly access 100 websites without raising suspicion. So, the first and most important step is to choose the correct proxy supplier.
2. Utilizing a Real User-Agent
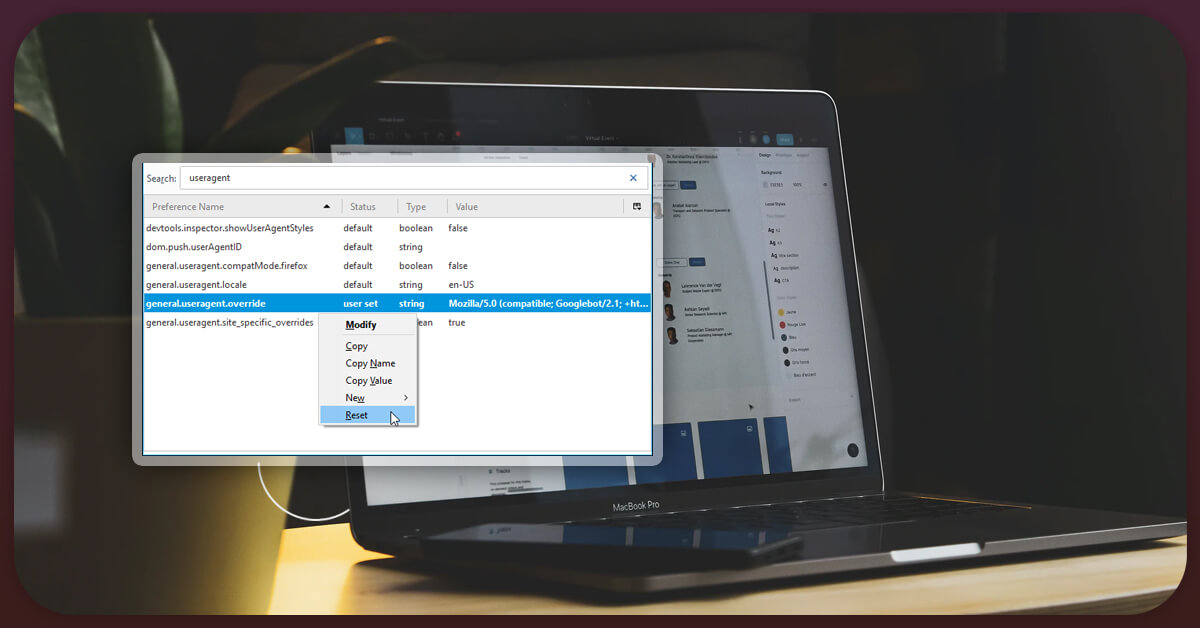
User-Agents fall in the category of HTTP header. Their main purpose is to figure out which browser you use to access a website. If you are accessing a non-major website, they can easily block you. For instance, Chrome and Mozilla Firefox are two famous browsers. Chances of getting blocked will reduce automatically if you prefer to utilize a user agent that appears legitimate and well-known.
It is possible to select one user agent that will best suit your requirement. For a complex website, a Googlebot user agent will assist you best. Googlebot will crawl the website as per your request. This will result in Google listing and the user agent will work best when updated. Each browser has its collection of user-agent strings. If you don't keep up with the times, you'll create suspicion, which you don't want. Switching between a few different user agents can benefit you.
3. Having Random Intervals between Request
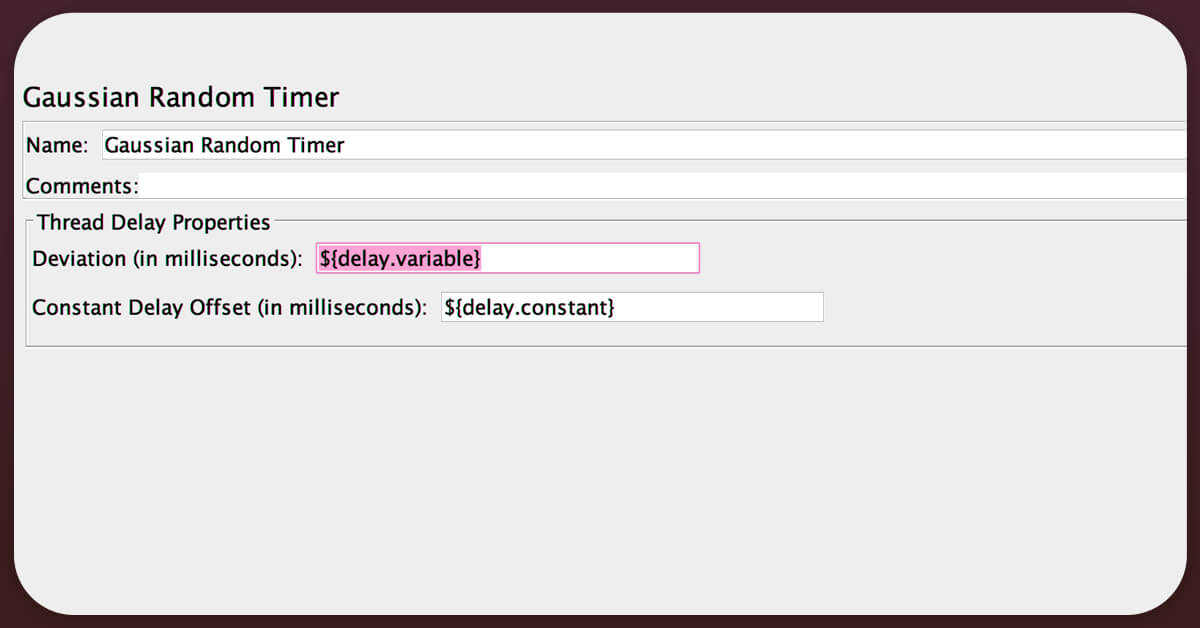
A web scraper works similarly to a robot. Web scraping software will request access at predetermined intervals. It should be your goal to look similar to humans. Because humans dislike routine, hence spacing out your requests at random intervals is preferable. You can simply avoid any anti-scraping program on the target website this way.
Ensure that your demands are reasonable. If you send requests very often, the website may collapse for everyone. For example, the main focus is to avoid loading the website. For example, Scrapy will slowly send the requests. Crawl-delay is specified in these publications. As a result, you can figure out how long you have to wait to avoid causing a lot of server traffic.
4. Referrer Always Assists
The referrer header is an HTTP request header that indicates where you were referred from. During any site scraping activity, this could be a lifeline. The idea is to appear as if you've come right from Google. Many websites link to certain referrers to divert traffic. To determine the most frequent referrals for a website, use a program like Similar Web.
Typically, these referrers are social media applications such as YouTube. You will appear more genuine if you know who referred you. As a result, the target website will recognize you as a genuine visitor and will not consider blocking you.
5. Avoiding any Honeypot Traps
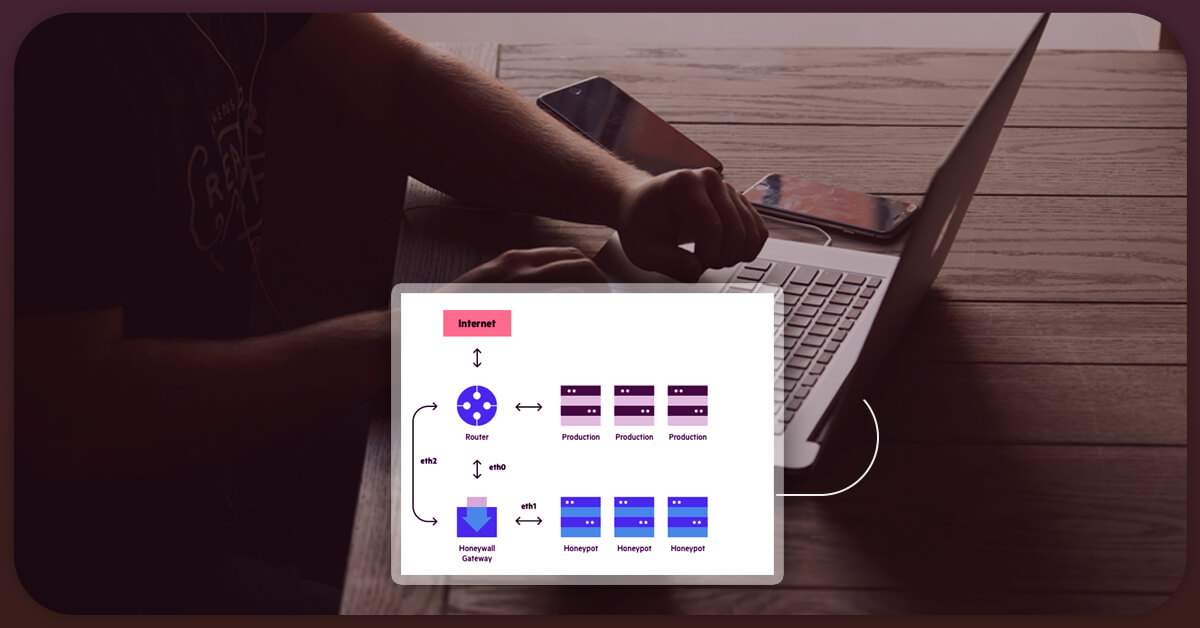
Website handlers become smarter as robots. Many websites include hidden connections that your scraping robots will visit. Websites might simply block your web data extraction operation by intercepting these robots. To be secure, look for the CSS values “display: none” or “visibility: hidden” in a link. It's important to backtrack if you notice these features in a link.
Websites can detect and capture any scraper using this strategy. Your requests can be fingerprinted and then blocked permanently. Web security experts employ this strategy to combat web crawlers.
6. Prefer Use of Headless Browsers
Nowadays, websites employ a variety of illusions to determine whether or not a visitor is authentic. For example, they can also browse cookies, JavaScript, fonts, and extensions. Web crawling of such websites will be a time-consuming task. In such situations, a headless browser can prove to be useful. Many tools exist to assist you in creating browsers that are comparable to those used by real people. This step will ensure that you remain undetected.
The creation of such sites is the only stumbling block in this strategy, as it necessitates more consideration and effort. As a result, it's the most effective strategy to scrape a website without being noticed. The only problem with smart tools is their CPU and memory. Prefer to use these tools if you've tried all other options for avoiding a website's blacklist.
7. Keep Website Changes in Check
Website layouts might vary for a variety of reasons. The majority of time, this is done to prevent scraping by other websites. Designs might appear in unexpected places on websites. This strategy is employed by even the most well-known websites. As a result, the crawler you're employing should then be capable of understanding these changes. Your crawler must be able to identify these continuous changes to continue scraping the web.
You may easily achieve this by keeping track of the number of successful requests per crawl. Another method to ensure constant monitoring is to write a test case for a particular target website. Each area of the website has a unique URL that you can use. This strategy will assist you in detecting any such modifications. You can avoid any pauses in the scraping process by sending just a few requests every 24 hours.
8. Employing a CAPTCHA Solving Service
CAPTCHAS are considered as most highly utilized web scraping tools. The majority of the time, crawlers are unable to evade captchas on websites. Various services are designed to carry out web scraping. Among those, AntiCAPTCHA is one of the CAPTCHAS solving solutions. Crawlers are required to apply CAPTCHA when visiting websites that require it. Most of these services may be inconvenient and costly. As a result, you'll need to make an informed decision to guarantee that this service isn't too costly for you.
iWeb Scraping is an expert service provider of Web Scraping Services. For further queries, contact us and request a quote!!