

How Web Scraping is Used to Gain Insights into a Particular Sector?

This blog will show how web scraping can help to achieve data for relevant analysis. Here, we will scrape the data for finding the average price of the children’s books and the ratio of how many people bought more children books during the covid crisis.
For scraping that data, here we will scrape the data available on knygos,lt and search for almost 200 books for children’s and teenagers which are sorted into 11 categories.
1. Scraping the Data
The first step is to examine the robots.txt file to ensure that the site can be scraped. Once this is confirmed, you can start scraping and importing the required libraries and creating the soup object.
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
from matplotlib import pyplot as plt
pd.options.mode.chained_assignment = None
ws = requests.get("https://www.knygos.lt/lt/knygos/zanras/literatura-vaikams-ir-jaunimui/")
soup = BeautifulSoup(ws.content, "html.parser")
Looking at the website's HTML file, you can see that the class for the book properties is named "book-properties," and it is separated into ".book-author," ".book-title," and ".book-price." I need to pick the class ".col-12" to limit the selection to the grid containing juvenile literature (otherwise we would include the promotions that are not related to our topic).
Each book has a star ranking system (going from 0 to 5). However, the range of these assessments is limited (between 4 and 5 stars for the vast majority). In order to assess a book's popularity, the number of reviews appears to be more important. This may be found under the class ".badge-secondary."
You can use a dictionary for data storage, with the key being the index and the value being a list comprising the author's name, title, number of reviews, and price.
book_dict = {}
for idx, book in enumerate(soup.select(".col-12 .book-properties-block")):
book_dict[idx] = []
for author in book.select(".book-author"):
book_dict[idx].append(author.get_text())
for title in book.select(".book-title"):
book_dict[idx].append(title.get_text())
for review in book.select(".badge-secondary"):
book_dict[idx].append(review.get_text())
for price in book.select(".book-price"):
book_dict[idx].append(float(price.get_text()[:-2].replace(',','.')))
The books are also divided into 11 categories- Knygos mažiausiems (books for toddlers), Knygos vaikams (books for children), Knygos paaugliams (books for teenagers), Pažintinė literatūra vaikams (Educational literature for children), Pasakos (Fairy tales), Kakė Makė (a popular Lithuanian children’s series featuring the character “Nelly Jelly”), Lavinamosios, užduočių knygelės (Educational and activity books), Veiklos knygelės (Workbooks), Kalėdinės knygelės (Christmas books), Mokiniams rekomenduojamos knygos (Books recommended by schools), Smagioji edukacija (Fun Education).
There are 16 books on this website for each category, so we can easily add those categories to the dictionary we constructed before.
categories_list = []
categories = soup.select("h2 a")
for element in categories:
categories_list.append(element.get_text()[1:].strip())
Categories = []
for element in categories_list:
for i in range(16):
Categories.append(element)
for i in range(176):
book_dict.get(i).append(Categories[i])
You will then have everything required to develop DataFrame. However, it is must to clean the data initially.
df_lithuania = pd.DataFrame.from_dict(book_dict, orient="index", columns=["name", "title", "review", "price", "category"])
df_lithuania["review"].replace('', 0, inplace=True)
df_lithuania["review"] = df_lithuania["review"].astype(int)
print(df_lithuania)
You will then be left with Dataframe that will consist of 176 rows and 5 columns


2. Price Analyzing
Let's have a look at which books and categories have received the most attention in our selection.
df_sorted_reviews = df_lithuania.sort_values(by="review", ascending=False) print(df_sorted_reviews.head()) dfg = df_lithuania.groupby(['category'])['review'].mean() dfg.plot(kind='bar', title='Reviews Children literature in Lithuania', ylabel='Mean reviews', xlabel='Categories', figsize=(15, 5))
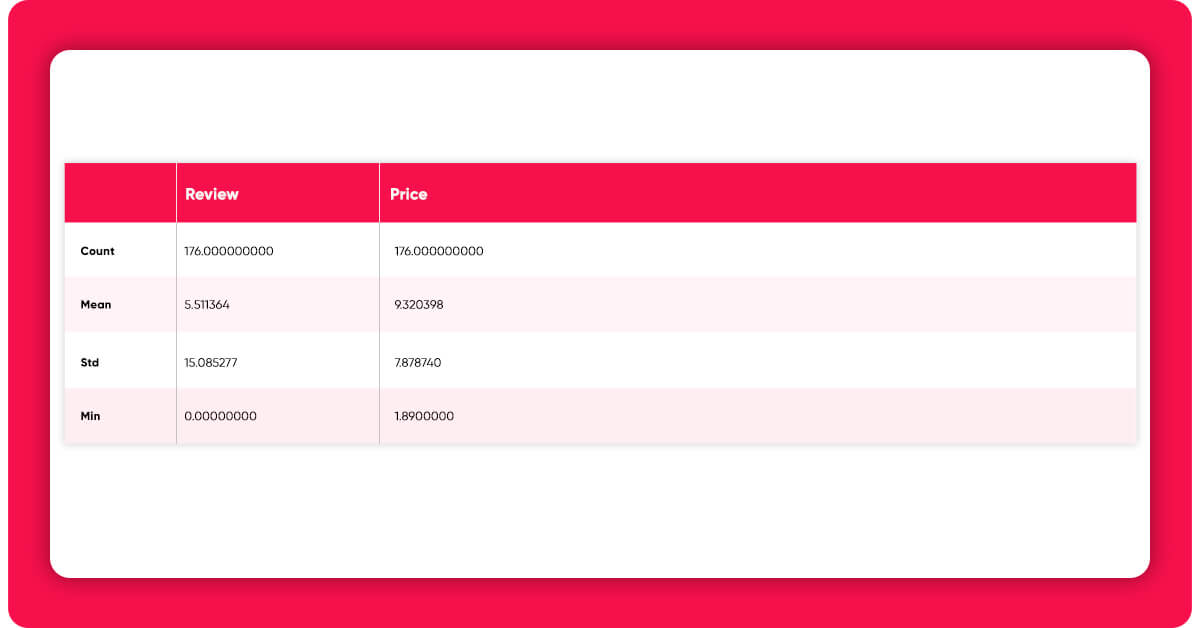

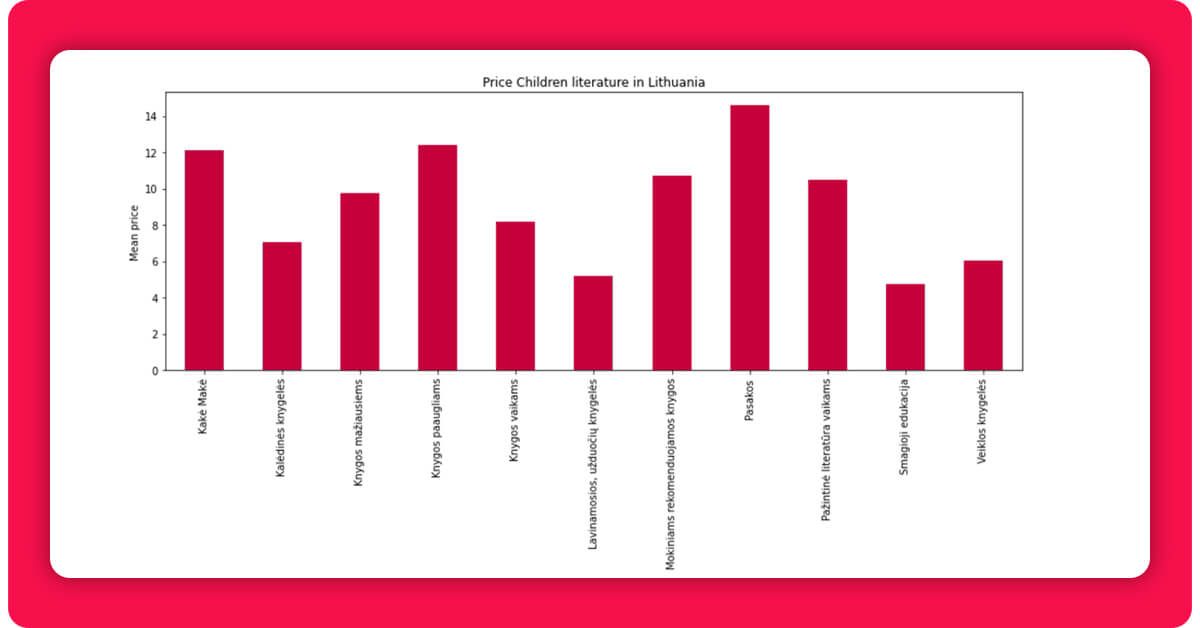
Fairy tales (pasakos) are the costliest genre, and accordingly, the most expensive book is likewise in this category. It should be emphasized, however, that this book is actually a compilation of volumes, therefore the high price.
2.3 Correlation between Price and Reviews
Here you will see that the more costly books don't appear to get many reviews. So, using df_Plithuania_no_outliers.plot.scatter(x="price", y="review", c="DarkBlue"), You can check whether there's a link between the two. Before that, you need to use df_lithuania_no_outliers = df_lithuania.drop ([73]) to eliminate the collection of volumes that was an obvious outlier.
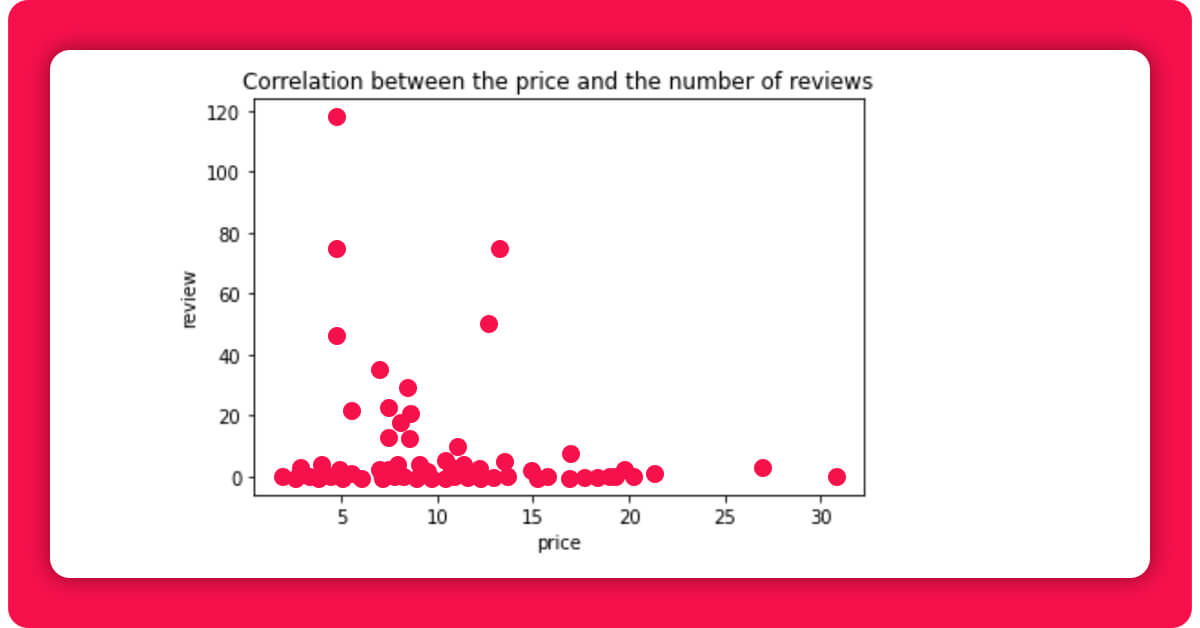
We can observe that the most rated publications are priced between 5 and 15 euros. However, as we discovered using the describe() method, about half of our books fall into this category. However, it is worth noting that publications that do not fit inside this range receive absolutely no reviews.
3. Author’s Nationality
One subject that caught the curiosity at the start of the investigation was the proportion of Lithuanian authors in this corpus. Without having to trace down the Lithuanian authors one by one, this appears to be a bit complicated. However, you can try to get around this by making use of one of the "quirks" of the Lithuanian language, which is its somewhat distinctive diacritical markings (""). These may be useful in determining which authors are likely to be Lithuanian (or of Lithuanian descent). You can divide the writers into two groups by using the regular expression module (import re).
It was noted that the search did appear to accept primarily Lithuanians, despite the fact that at least two people of non-Lithuanian nationality were included in the selection (Pavla Hanáková and Ester Dobiáová, both of Czech descent).
The third addition to the list is indeed the inclusion of several Lithuanian common names (Vytautas, Linas) and, ultimately, the addition of Ruta Sepetys (author of Between Shades of Gray), whose dual nationality may be responsible for the lack of "u".
Despite the fact that she resides in the United States, her book's overall topic is strongly tied to Lithuania. As a result, it is logical to consider her among Lithuanian authors. The whole code is as follows:
lit = "[ąčęėįšųūžĄČĘĖĮŠŲŪŽ]"
lit_author = []
for author in df_lithuania["name"]:
if re.search(lit, author):
lit_author.append(author)
elif "Vytautas" in author:
lit_author.append(author)
elif "Linas" in author:
lit_author.append(author)
elif "Ruta" in author:
lit_author.append(author)
lit_author.remove("Pavla Hanáčková")
lit_author.remove("Ester Dobiášová, J...")
We now know that the percentage of Lithuanian authors in our corpus is 19.32% thanks to this list. The next step would be to add a new column to our DataFrame with a "Y" if the author is Lithuanian and a "N" otherwise. This new column will help us to determine whether Lithuanian writers obtain more reviews than non-Lithuanian authors.
df_lithuania["lithuanian"] = "N"
for i in range(len(df_lithuania.index)):
for author in lit_author:
if df_lithuania["name"].iloc[i] == author:
df_lithuania["lithuanian"].iloc[i] = "Y"
break
else :
df_lithuania["lithuanian"].iloc[i] ="N"
continue
review_lit = df_lithuania.groupby("lithuanian")["review"].sum()
Lithuanian_average = round(review_lit["Y"]/34, 2)
Non_Lithuanian_average = round(review_lit["N"]/142, 2)
This computation shows that novels published by Lithuanians obtain an average of 9.56 reviews, whereas books authored by non-Lithuanians receive just 4.39 reviews. We do know of one outlier: the book Between Shades of Gray, which has 118 reviews. Let’s see how it changes if we take it out of our corpus.
df_lithuania_no_sepetys = df_lithuania.drop(159)
review_lit = df_lithuania_no_sepetys.groupby("lithuanian")["review"].sum()
Lithuanian_average = round(review_lit["Y"]/33, 2)
Non_Lithuanian_average = round(review_lit["N"]/143, 2)
Without Sepetys' book, the average falls to 6.27 reviews, which is still higher than the national average for foreign writers.
4. Comparison of Top Seller Books from 2019 to 2021
On knygos.lt, you can observe that a huge number of children's literary books are among the year's best-sellers. I'd like to know if the proportion has changed over time, and if the covid issue has had any effect. However, our website does not provide the prior year's top 100. As a result, we must visit another website, www.knyguklubas.lt. This site necessitates the activation of JavaScript, which Beautiful Soup does not allow. As a result, we must use another Python library: Selenium.
To compare 2019 and 2021, you can choose to obtain a list of children's writers from this website and then compare the proportion of authors in the top sales in 2019 and 2021.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.implicitly_wait(8)
driver.get("https://www.knyguklubas.lt/literatura-vaikams?product_list_limit=96&product_list_order=most_reviews")
You can visit to the section of the website dedicated to children's literature (set to 96 books sorted by popularity). The writers from the top two pages were then scraped, giving me a list of 192 popular authors in the subject of children's literature. Then removed the "Nra Autoriaus" (no author) with a list comprehension, yielding a final list of 172 writers.
button = driver.find_element( By.XPATH, '/html/body/div[3]/div[3]/div[1]/div/div[2]/div/div/div/div/div[1]/a') button.click() full_list = [] authors = driver.find_elements( By.XPATH, '/html/body/div[2]/main/div[4]/div[1]/div[3]/div[3]/ol/li/div/div[2]/div[1]/p') for author in authors: full_list.append(author.text) next = driver.find_element( By.XPATH, '/html/body/div[2]/main/div[4]/div[1]/div[3]/div[4]/div[2]/ul/li[6]') next.click() authors = driver.find_elements( By.XPATH, '/html/body/div[2]/main/div[5]/div[1]/div[3]/div[3]/ol/li/div/div[2]/div[1]/p') for author in authors: full_list.append(author.text) full_list_no_na = [value for value in full_list if value != 'Nėra Autoriaus']
You can then visit the website with the most popular novels of 2019 and put all of the writers to a list, and do it same for 2021.
# Get the list of top authors from 2019
name_author = '/html/body/div[2]/main/div[3]/div/div[2]/div[2]/div[4]/div[1]/ol/li/div/div[2]/div[1]/p'
driver.get("https://www.knyguklubas.lt/2019-uju-top-100?pyaavi=1")
authors_2019 = []
wait = WebDriverWait(driver, 10)
element = wait.until(EC.element_to_be_clickable((
By.XPATH, name_author)))
authors_1 = driver.find_elements(
By.XPATH, '/html/body/div[2]/main/div[3]/div/div[2]/div[2]/div[4]/div[1]/ol/li/div/div[2]/div[1]/p')
for author in authors_1:
authors_2019.append(author.text)
driver.get("https://www.knyguklubas.lt/2019-uju-top-100?pyaavi=2")
element = wait.until(EC.element_to_be_clickable((
By.XPATH, name_author)))
authors_2 = driver.find_elements(
By.XPATH, name_author)
for author in authors_2:
authors_2019.append(author.text)
# Get the list of top authors from 2021
driver.get("https://www.knyguklubas.lt/populiariausios-metu-knygos")
authors_2021 = []
element = wait.until(EC.element_to_be_clickable((
By.XPATH, '/html/body/div[2]/main/div[4]/div[1]/div[2]/div[2]/div[4]/div[1]/ol/li/div/div[2]/div[1]/p')))
authors_wb = driver.find_elements(
By.XPATH, '/html/body/div[2]/main/div[4]/div[1]/div[2]/div[2]/div[4]/div[1]/ol/li/div/div[2]/div[1]/p')
for author in authors_wb:
authors_2021.append(author.text)
At last, we will check if there are any children author in 2019 or 2021
children_author_2019 = [] children_author_2021 = [] for author in full_list_no_na: if author in authors_2019: children_author_2019.append(author) if author in authors_2021: children_author_2021.append(author)
There are no children's writers among the 95 books published in 2019, however there are 18 novels written by children's authors among the 97 books published in 2021.
We can scrape the data using Python but it will be time-consuming task. Hence, for simple web scraping services, contact iWeb Scraping today!!
Request for a quote!