

How To Scrape Walmart for Product Information Using Python?

Walmart is one of the largest retailers in the world. It has around 4,500 stores in the United States and over 11,000 stores worldwide. This makes Wal-Mart a great place to find product information and data for your project!
The goal of this tutorial is to provide you with a step-by-step guide on scraping product information from Walmart using Python.
What Is Walmart Product Data?
Walmart Product Data is an extensive collection of data that can help you to make better decisions. It includes information about every single product sold by Walmart and provides valuable insights into its performance, market share, and sales history.
Walmart Product Data allows you to quickly compare products in terms of sales volumes, price points, and other important metrics such as customer ratings and reviews.
With Walmart Product Data, you can:
- Analyze product sales trends over time.
- Compare your products against competitors’ products.
- Identify new opportunities for growth by identifying similar products that have been successful for other brands.
Importance of Walmart Product Data
Walmart offers product data to help customers find what they need more quickly. This makes it easier for customers to find what they want when they shop at Walmart.com, which can increase sales for the company. As a result, Walmart can provide better service for its customers and make more money.
Customers can use Walmart’s product data to make smarter decisions about buying or selling online through eBay or Amazon Marketplace. For example, if you want to sell something that isn’t available on Walmart’s website, you can use its product data to see precisely what people are looking for so that you know how much money you should ask for your item.
Why Scrape Walmart Product Data?
There are many reasons why you would want to scrape Walmart product data. If you are a marketer, it is a valuable resource for building your private-label products. This is because
Walmart has the largest selection of consumer goods, and the prices are competitive with Amazon. And if you are a reseller, scraping Walmart data will allow you to scale your business quickly by sourcing products directly from their website.
The most common use case is scraping Walmart product data to create a searchable database of products. This allows you to build up inventory quickly while providing a valuable resource for others in your industry. The best part is that there are multiple ways of scraping Walmart data, so you can choose whichever method works best for your business model!
How To Scrape Walmart Product Data Using Python
The first step is to create a folder and install libraries. For now, we will install two libraries - requests and beautiful soup.
python -m pip install requests bs4 pandas
The following command will install three libraries--Requests and BeautifulSoup. Let's take a look at each of them:
- Requests make it simple to make HTTP requests.
- BeautifulSoup helps us make HTML parsing a breeze.
Now that you have the necessary packages installed, it is time to start writing the script.
Fetching Walmart Product Page
Begin by importing the necessary libraries, as follows:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Let's try scraping Walmart's iPhone 11 product page.
response =
requests.get("https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-11-64GB-Black-Prepaid-Smartphone-Locked-to-Straight-Talk/665592882?adsRedirect=true")
print(response.status_code)
Once you run this code, you will likely see a status code of 200. Let's use BeautifulSoup to parse the content of the response to validate if it's working properly.
soup = BeautifulSoup(response.content, 'html.parser') print(soup.get_text())
If you are lucky, you might get an HTML of the web page. But most likely, you will get something like this:
Robot or Human?
Activate and hold the button to confirm that you're human. Thank You!
Try a different method
Terms of Use
Privacy Policy
Do Not Sell My Personal Information
Request My Personal Information
© Walmart Stores, Inc.
Let's examine what happened here. It's evident that Walmart has blocked the script, and a CAPTCHA page has been displayed to prevent you from accessing the product using a script. Nevertheless, this should not stop you--there are alternative approaches to get past this roadblock, and we'll explore them in the next section.
Avoid Detecting Using Headers
To prevent detection, include a User-Agent header with the request. Websites often use these headers to determine what kind of device is browsing a URL. To obtain this header, use developer tools in your web browser. To access them, follow the steps below:
To identify the user agent of a website:
- Open the Chrome browser and navigate to the Walmart product page.
- Right-click on the page and select Inspect to open the developer tools.
- Click on the Network tab and refresh the page (F5 or Ctrl+R).
Then click on the first item in the list of requests in the Network tab.
Finally, click on the first item in the list of requests that appears in the Network tab and use its value as follows:
walmart_product_url =
'https://www.walmart.com/ip/AT-T-iPhone-14-128GB-Midnight/1756765288'
headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHT)}
response = requests.get(walmart_product_url, headers-headers)
soup = BeautifulSoup (response.content, 'html.parser')
print (soup.prettify())
Once you run the script again, you will see that the correct product page HTML is now being generated.
Extracting Walmart product information
Before you can start scraping data, you must understand how to locate the elements you want to extract. You can find these elements by inspecting the page's structure using developer tools like FireBug. For this tutorial, we'll extract the title and price from a product listing.
Select Product Title
To find the title of your product, use developer tools and select the title with your cursor. Then right-click on it and choose Inspect. It would help if you got a window that looks like this:
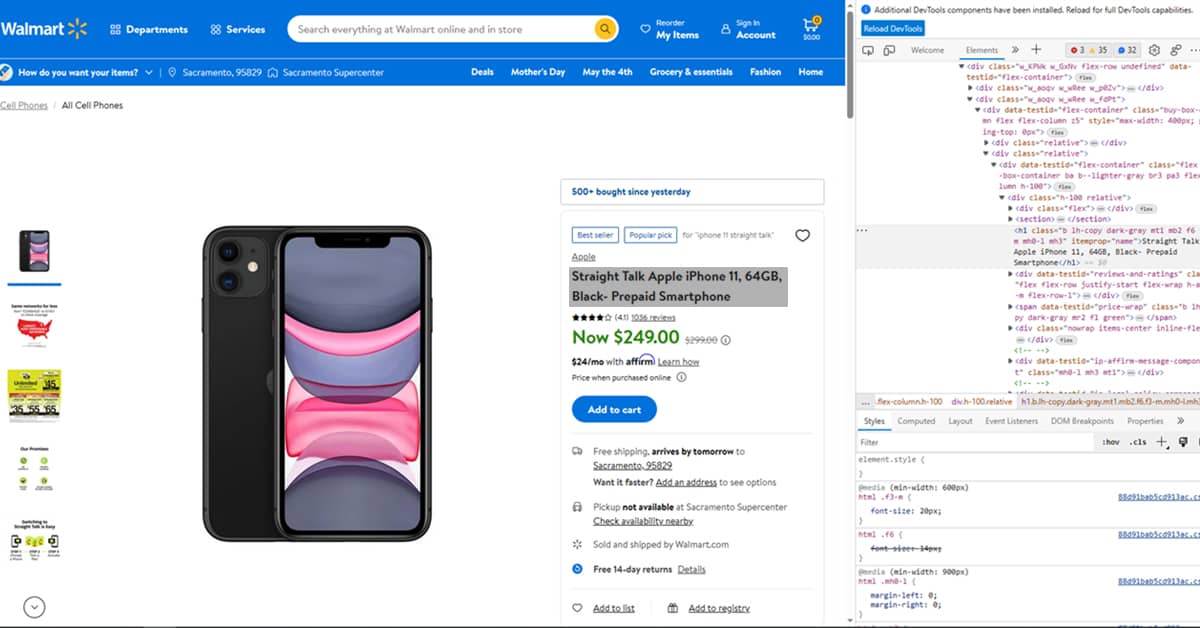
We will use BeautifulSoup, a widely-used and user-friendly library for web scraping. The product title is placed within an h1 tag, which indicates how to reference it in the code. You can instruct BeautifulSoup to scrape the product title using the following code:
title = soup.find('h1').text
Scraping Product Price
To get product pricing information, locate the price on the website. Hover your mouse over it, right-click, and select Inspect Element.
You'll see that the price is in a span tag. To select this tag with Python and Beautiful Soup, you can use the same syntax you used previously.
Export Data to CSV
You can use the product_data list to store the results in a CSV file, which will be much more helpful than HTML format because you can open it in Excel. The Pandas Library will help you do that.
Start by initializing an empty data frame using the code below:
df = pd.DataFrame(columns='title','price'])
Next, add the product list to the data frame
df = df.append(product_data)
Finally, store the data frame in a CSV file named result.csv.
df.to_csv('result.csv', index=False)
You should now be familiar with scraping name and price data. However, You probably need to find out if you can scrape multiple products simultaneously. The answer is yes. Use a for loop to iterate over the product URLs:
import requests
from bs4 import BeautifulSoup
import pandas as pd
product_urls = ["https://www.walmart.com/ip/AT-T-iPhone-14-128GB-Midnight/1756765288", "https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-14-Pro-12 8GB-Silver-F]
headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, lik) }
product_data = []
for url in product_urls:
response = requests.get(url, headers-headers)
soup = BeautifulSoup (response.content, 'html.parser')
title = soup.find("h1").text
price = soup.find("span", {"itemprop": "price"}).text
product_data.append({
"title": title,
"price": price,
})
The code shown above is self-explanatory. First, it loops through all product links on Walmart's website, scraping each product page using BeautifulSoup. Afterward, it stores the result in a list named product_data. Finally, Pandas creates a CSV file with the product data from each web page.
Wrapping Up
This scraper guide will help you scrape the data from Walmart to import it into Python and analyze it to understand your target audience better. You can use these insights to make a marketing strategy to determine where to focus your efforts.