

How Web Scraping is Used for Extracting LinkedIn Companies Using Selenium and BeautifulSoup?

For starting a new project, using web scraping services is the best option that can provide data sets offered by various sites. You wish to scrape the specific number of posts from every company and then execute Machine Learning methods.
What Kind of Information Will You Scrape from the Website?
- Name
- Date
- Post
- Likes
Examine the Web Page
Go to examine by pressing F12 or right-clicking on the page.
A basic understanding of "HTML" is required. However, you can click on almost any data on the page that interests you, and you will be taken to the exact spot on the HTML lines coding.
Python Script
The magic will be performed by these two Python languages (BeautifulSoup and Selenium). By following the instructions, you can configure Selenium and the web driver.
The first step is to import the libraries into Python.
from selenium import webdriver from bs4 import BeautifulSoup from time import sleep import pandas as pd
We'll start by creating an example, then run a browser in private mode and expand the window.
options=webdriver.ChromeOptions()
options.add_argument('--incognito')
driver=webdriver.Chrome(options=options)
driver.get('https://www.linkedin.com/uas/login')
driver.maximize_window()
To log in, we'll send our credentials (username and password).
username = driver.find_element_by_id('username')
username.send_keys('your_username')
password = driver.find_element_by_id('password')
password.send_keys('your_password')
log_in_button = driver.find_element_by_class_name('from__button--floating')
log_in_button.click()
You will need to add the URLs of the firms that you want to scrape to the list.
urls = [ 'https://www.linkedin.com/company/alicorp-saa/posts/?feedView=all','https://www.linkedin.com/company/backus/posts/?feedView=all' ]
Let us create a dictionary for saving the data
data = {
"name": [],
"date": [],
"post": [],
"likes": [],
"count_posts":[]
}
You'll need to modify this and see how many scrolls you'll have, and we'll also have to include a variable delay to reload the site.
for i in range(max(0,40)):
driver.execute_script('window.scrollBy(0, 500)')
sleep(1)
BeautifulSoup will parse HTML when the vehicle has completed the above step, allowing us to collect whatever we require. For instance, let's say we require post content.
posts=soup.find_all('div',{'class':"occludable-update ember-view"})post = posts[2].find('div',{'class':"feed-shared-update-v2__description-wrapper ember-view"}).span.get_text()
if post:
print(post)
Output:
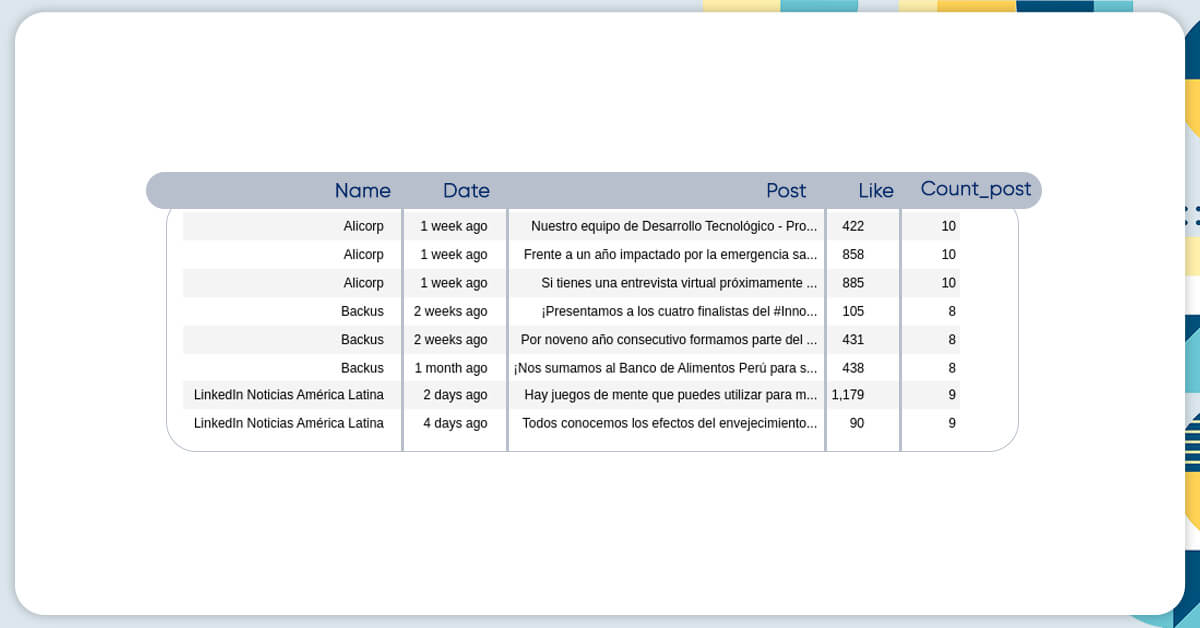
Put Data into DataFrame
df = pd.DataFrame(data) df.head(10)
For Any Queries, Contact iWeb Scraping!!



